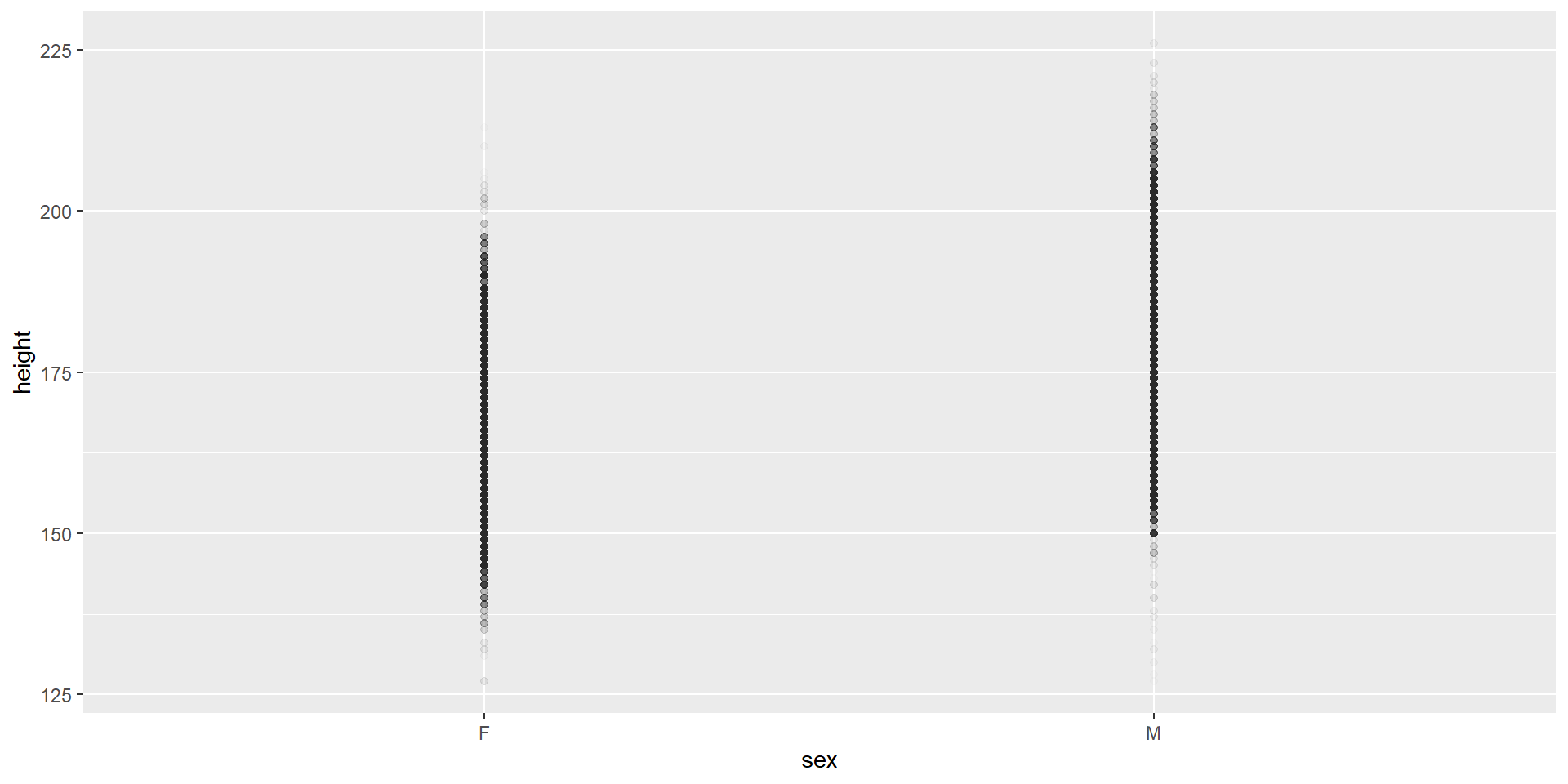
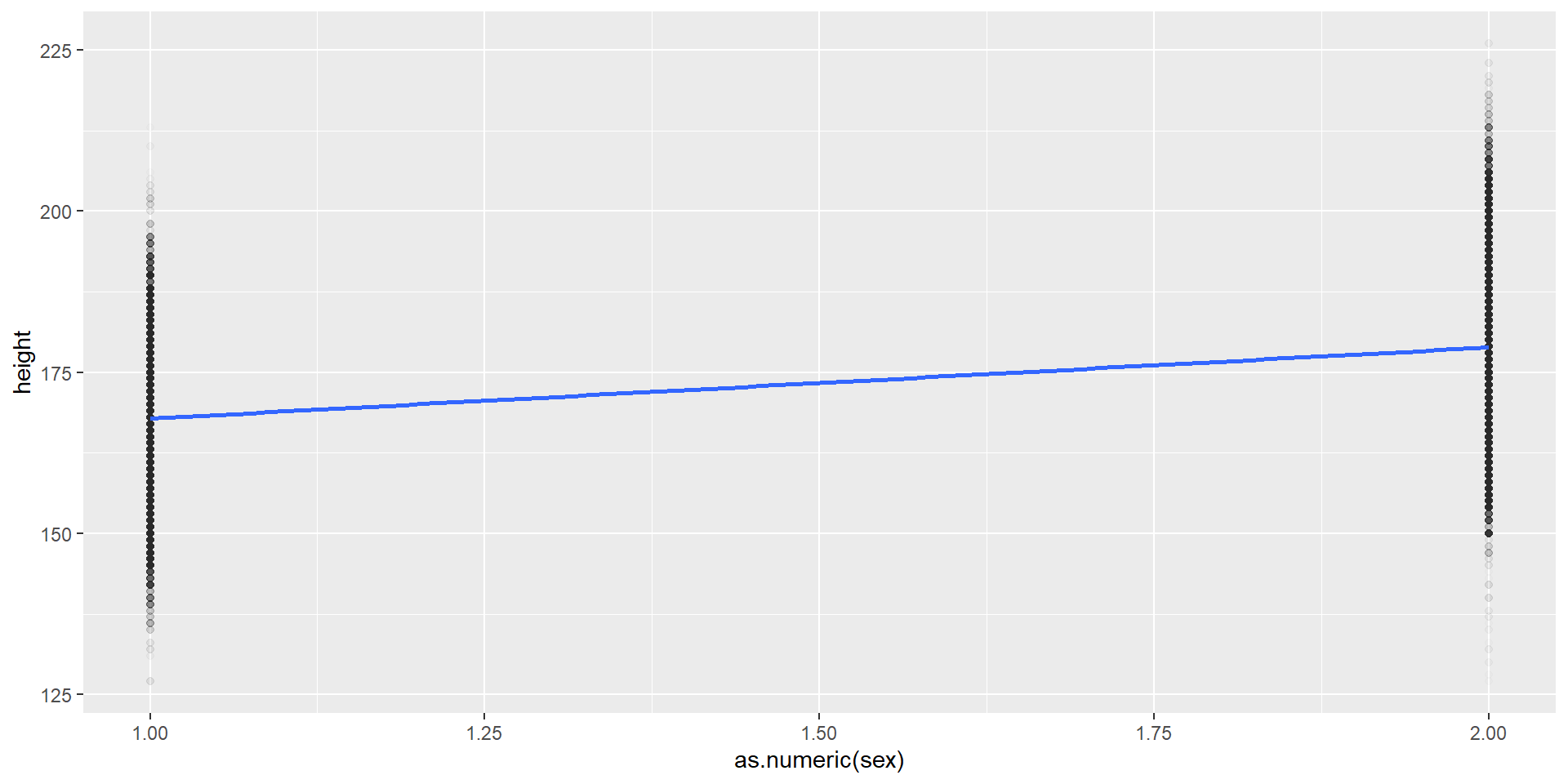
# bei nur diskreten Prädiktoren funktioniert geom_smooth(method = "lm") nicht, daher konvertieren wir zu numerischggplot(olympics, aes(x =as.numeric(sex), y = height)) +geom_point(alpha =0.01) +geom_smooth(method ="lm", se =FALSE)
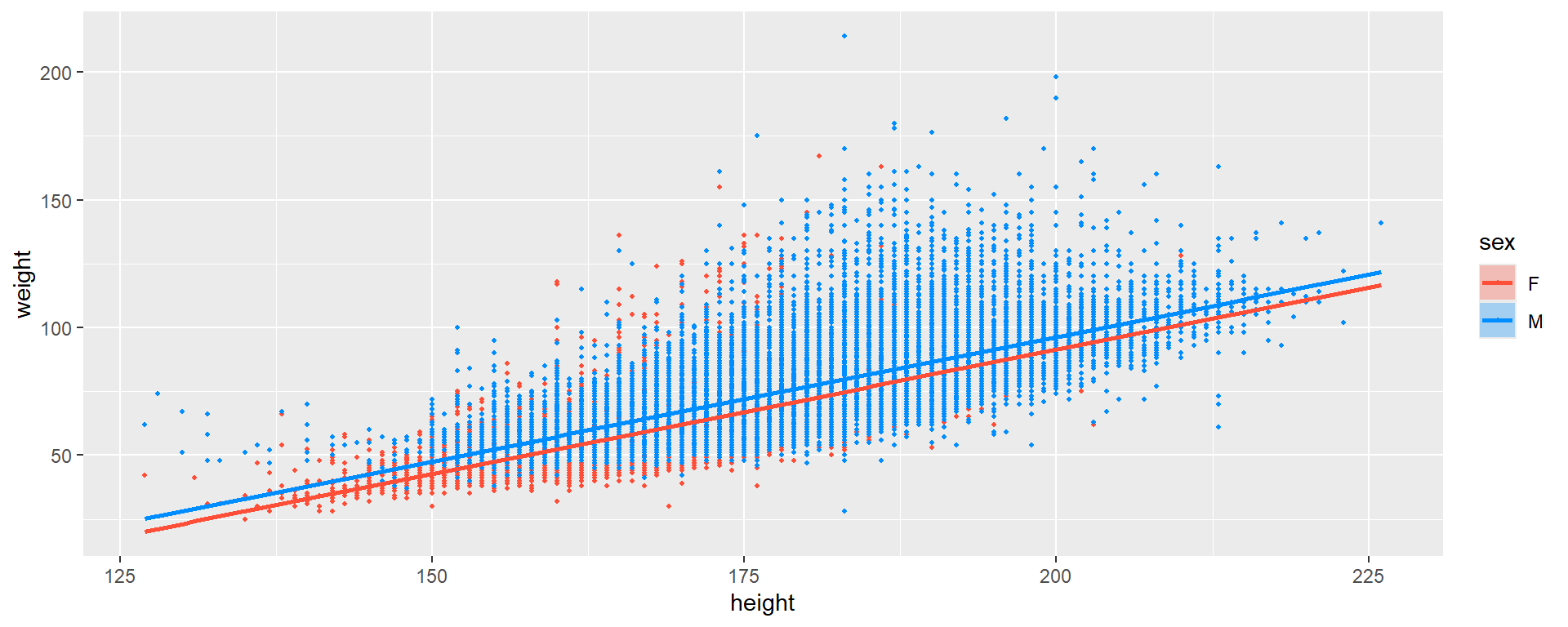
# geom_smooth(method = "lm") malt Linien die nicht zwingend parallel sind, daher nutzen wir visregvisreg(multi_mod, xvar ="height", by ="sex", overlay =TRUE, gg =TRUE)
a <-10:70h <-120:220new <-expand.grid(height = h, age = a, KEEP.OUT.ATTRS =FALSE)new$weight <-predict(mod_age, newdata = new)r <- reshape2::acast(new, age ~ height, value.var ="weight")plotly::plot_ly(olympics, x =~height, y =~age, z =~weight, type ="scatter3d", marker =list(size =2), mode ="markers") |> plotly::add_trace(x = h, y = a, z = r, type ="surface")