viewof b = Inputs.range([-5,5], {value:2,step:0.1,label:"Intercept"})viewof m = Inputs.range([-3,3], {value:1,step:0.1,label:"Slope"})functionlineData(b, m){const pts = [];for(let x =-10; x <=10; x +=0.5) pts.push({x,y: b + m * x});return pts;}
Root of Mean Squared Error (RSME): “Durchschnittliche” Abweichung
Ziel: Parameter so wählen, dass RSME minimiert wird
Interaktives Beispiel
import {Inputs} from"@observablehq/inputs"viewof b2 = Inputs.range([-5,5], {value:2,step:0.1,label:"Intercept"})viewof m2 = Inputs.range([-3,3], {value:1,step:0.01,label:"Slope"})// five sample points near y = 2 + 1*x with controlled noise (RMSE ≈ 1.75 at b=2,m=1)data2 = [ {x:-4,y:-0.8}, {x:-2,y:-2.4}, {x:0,y:2.0}, {x:2,y:6.4}, {x:4,y:4.8}]functionpredict2(b, m, x){ return b + m * x }functionresiduals2(b, m){return data2.map(d => ({x: d.x,y: d.y,yhat:predict2(b, m, d.x),resid: d.y-predict2(b, m, d.x)}));}// show RMSE in the sidebar (no imports, no const)rmse2 =Math.sqrt(residuals2(b2, m2).reduce(function(s,p){return s + p.resid*p.resid},0) /residuals2(b2, m2).length)html`<div style='font-family:sans-serif;margin-top:8px'>RMSE: <strong>${rmse2.toFixed(2)}</strong></div>`
pts2 =residuals2(b2, m2)linePts2 = [{x:-10,y:predict2(b2, m2,-10)}, {x:10,y:predict2(b2, m2,10)}]// build two-point segments grouped by gid so each draws as a vertical linesegs = pts2.flatMap((p, i) => [{x: p.x,y: p.y,gid: i}, {x: p.x,y: p.yhat,gid: i}])Plot.plot({width:600,height:400,x: {domain: [-10,10]},y: {domain: [-10,10]},marks: [ Plot.line(linePts2, {x:"x",y:"y",stroke:"steelblue",strokeWidth:3}), Plot.line(segs, {x:"x",y:"y",z:"gid",stroke:"tomato",strokeWidth:1.5}), Plot.dot(pts2, {x:"x",y:"y",fill:"#000",r:5}), Plot.dot(pts2, {x:"x",y:"yhat",fill:"steelblue",r:3}), Plot.ruleY([0], {stroke:"#333"}), Plot.ruleX([0], {stroke:"#333"}) ]})
Lineares Modell fitten in R
# Datensatz aus interaktivem Beispieldf_demo <-data.frame(x =c(-4, -2, 0, 2, 4), y =c(-0.8, -2.4, 2.0, 6.4, 4.8))# Lineares Modell fitten# y wird vorhergesagt (~) durch x, unter Nutzung des Datensatzes df_demomod <-lm(y ~ x, data = df_demo)s <-summary(mod)s$sigma
[1] 2.19089
Modellevaluation 1: Gesamtmodell
Residual Standard Error (RSE): Eine Variante vom RMSE
R²: Anteil der Streuung, die durch das Modell erklärt wird (100% = alle Punkte liegen auf der Linie)
F-Statistik & p-Wert: Ist das Modell besser als nur der Mittelwert?
name sex age height weight nation noc games
1 A Dijiang M 24 180 80 China CHN 1992 Summer
2 A Lamusi M 23 170 60 China CHN 2012 Summer
3 Gunnar Nielsen Aaby M 24 NA NA Denmark DEN 1920 Summer
4 Edgar Lindenau Aabye M 34 NA NA Denmark/Sweden DEN 1900 Summer
5 Christine Jacoba Aaftink F 21 185 82 Netherlands NED 1988 Winter
6 Christine Jacoba Aaftink F 21 185 82 Netherlands NED 1988 Winter
year season city sport event medal
1 1992 Summer Barcelona Basketball Basketball Men's Basketball <NA>
2 2012 Summer London Judo Judo Men's Extra-Lightweight <NA>
3 1920 Summer Antwerpen Football Football Men's Football <NA>
4 1900 Summer Paris Tug-Of-War Tug-Of-War Men's Tug-Of-War Gold
5 1988 Winter Calgary Speed Skating Speed Skating Women's 500 metres <NA>
6 1988 Winter Calgary Speed Skating Speed Skating Women's 1,000 metres <NA>
nrow(olympics)
[1] 271116
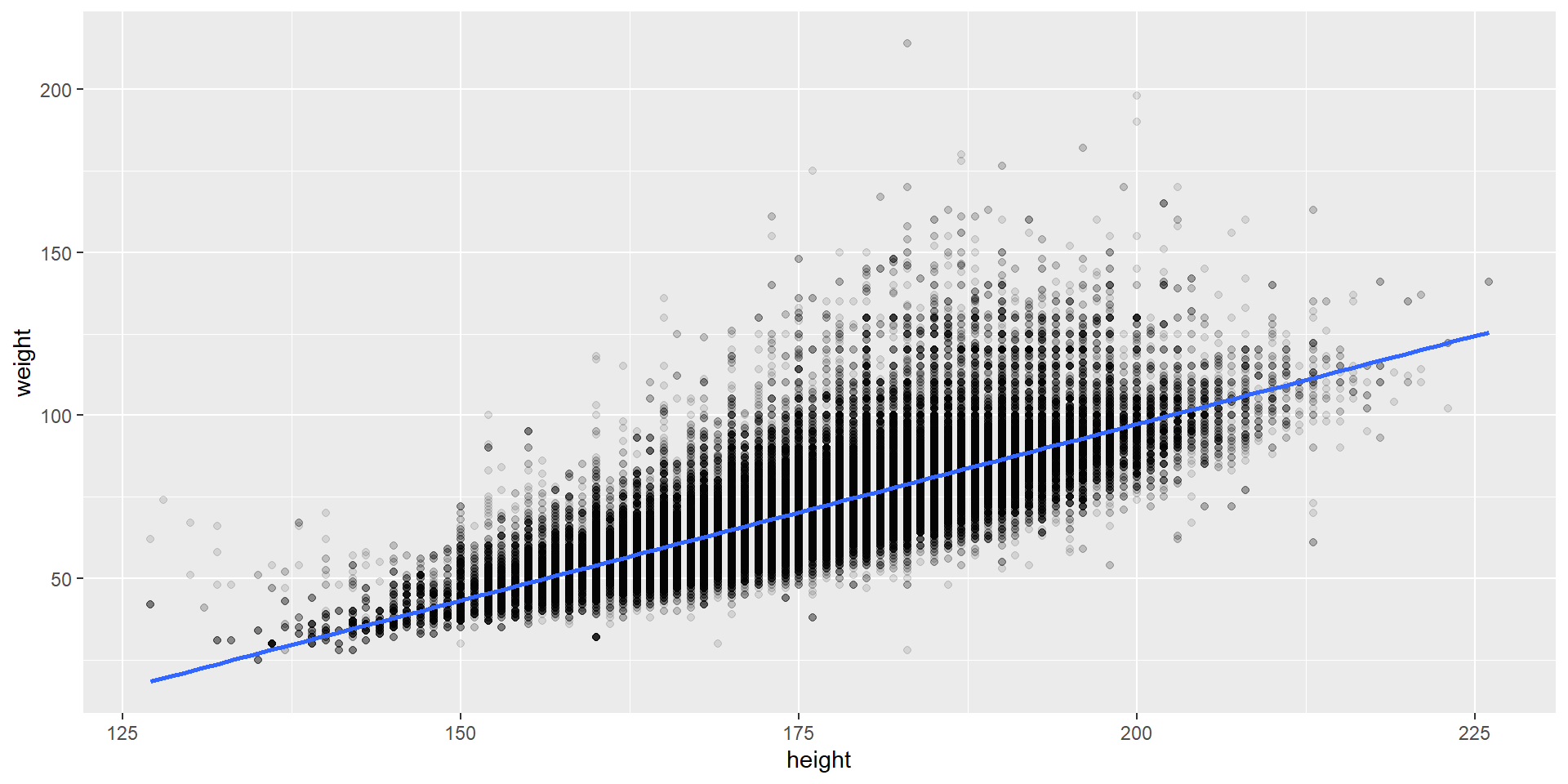
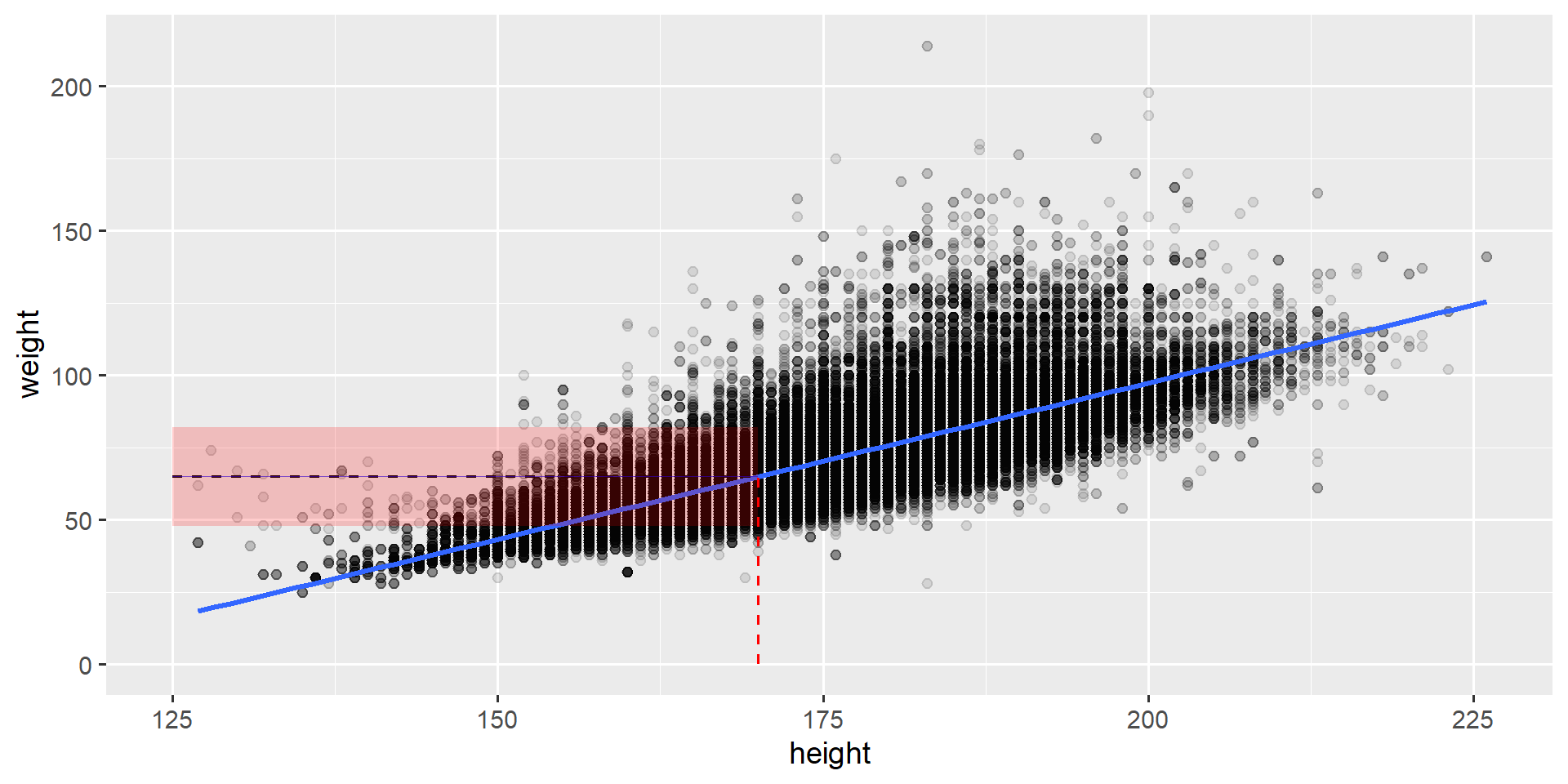
Visualisierung
library(ggplot2)ggplot(olympics, aes(x = height, y = weight)) +geom_point(alpha =0.1) +geom_smooth(method ="lm", se =FALSE)
Lineares Modell
\[weight = \beta_0 + \beta_1 height \]
mod_olympics <-lm(weight ~ height, data = olympics)